AdaGrasp: Learning an Adaptive Gripper-Aware Grasping Policy

This paper aims to improve robots’ versatility and adaptability by allowing them to use a large variety of end-effector tools and quickly adapt to new tools. We propose AdaGrasp, a method to learn a single grasping policy that generalizes to novel grippers. By training on a large collection of grippers, our algorithm is able to acquire generalizable knowledge of how different grippers should be used in various tasks. Given a visual observation of the scene and the gripper, AdaGrasp infers the possible grasping poses and their grasp scores by computing the cross convolution between the shape encodings of the input gripper and scene. Intuitively, this cross convolution operation can be considered as an efficient way of exhaustively matching the scene geometry with gripper geometry under different grasp poses (i.e., translations and orientations), where a good “match” of 3D geometry will lead to a successful grasp. We validate our methods in both simulation and real-world environments. Our experiment shows that AdaGrasp significantly outperforms the existing multi-gripper grasping policy method, especially when handling cluttered environments and partial observations.
Paper
Latest version: arXiv
International Conference on Robotics and Automation (ICRA) 2021

Team




Columbia University in the City of New York
BibTeX
@inproceedings{xu2021adagrasp,
title={AdaGrasp: Learning an Adaptive Gripper-Aware Grasping Policy},
author={Xu, Zhenjia and Qi, Beichun and Agrawal, Shubham and Song, Shuran},
booktitle={Proceedings of the IEEE International Conference on Robotics and Automation},
year={2021}
}Technical Summary Video
Grasp Score Visualization
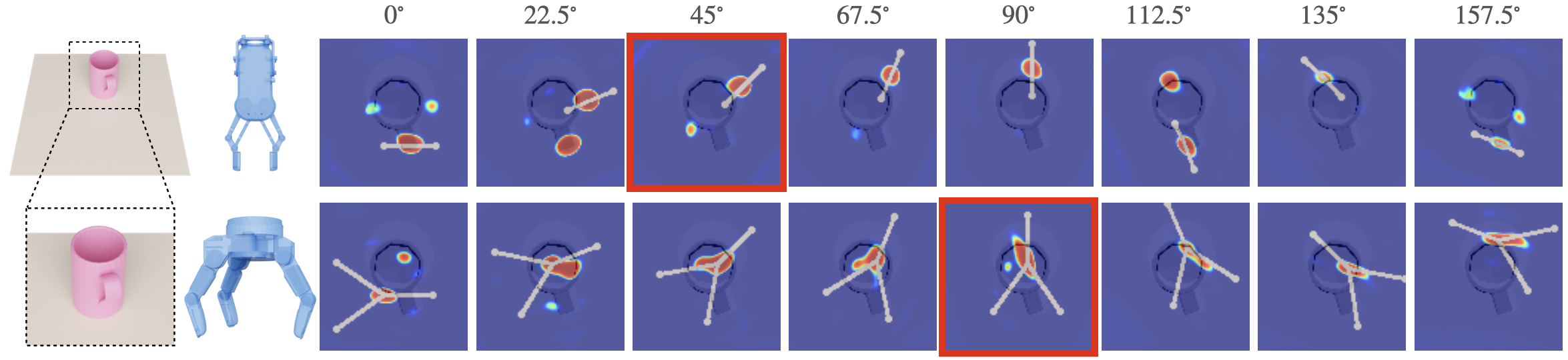
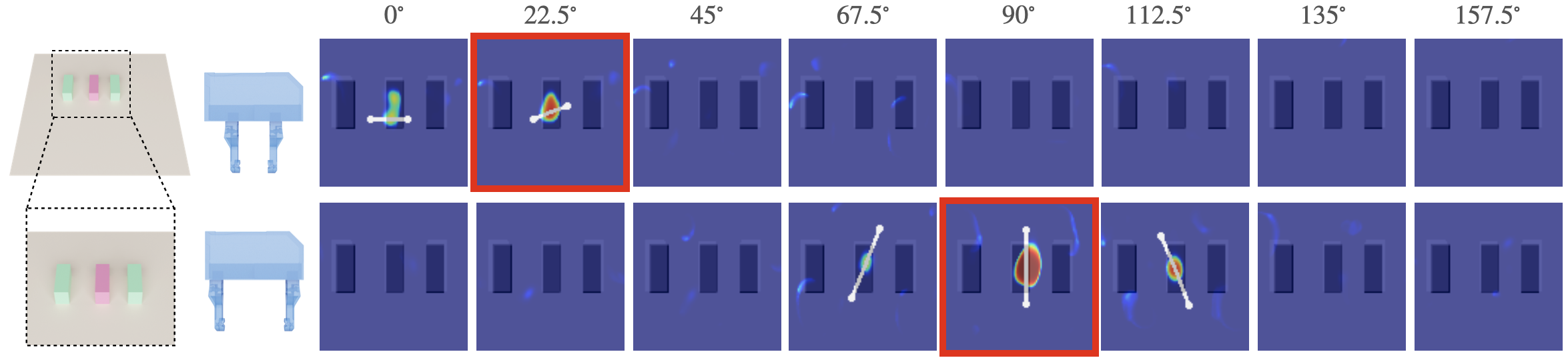
AdaGrasp is able to infer diverse grasp poses that are suitable for each input gripper and configuration. On the left, the policy predicts the grasp score for the RG2 and Barrett Hand gripper with a target mug. RG2 prefers to grasp the cup’s edge or handle, while BarrettHand prefers to grasp across the whole cup. On the right scene, the target object (red) is surrounded by two obstacles (green). We visualize the grasp poses for the WSG50 gripper under different initial configurations. With a larger opening, the algorithm chooses to grasp vertically (90°) to avoid collisions, while with a smaller opening, it chooses to grasp horizontally (22.5°) since the object’s length is now larger than the gripper width.
Simulation Expariments
Training Grippers
Testing Grippers
Given the same input scene, AdaGrasp predicts a different grasp pose suitable to each gripper. Here are example grasps inferred by the algorithm for training grippers and testing grippers in multi-object setups (scene 1-2), and multi-object+ obstacle setups (scene 3).
Real-World Expariments
Single Object
RG2
WSG-50
Barrett Hand-B
Barrett Hand
Multiple Objects
RG2
WSG-50
Barrett Hand-B
Barrett Hand
Acknowledgements
We would like to thank Lin Shao and Unigrasp authors for sharing code and models for comparison, Iretiayo A. Akinola for his help in setting up BarretHand Gripper and Google for the UR5 robot hardware. This work was supported in part by the Amazon Research Award and the National Science Foundation under CMMI-2037101.
Contact
If you have any questions, please feel free to contact Zhenjia Xu.